Article. What i write
I deepfake: come rilevarli per difendersi dalla disinformazione
Pubblicato il 08 novembre 2024 su CyberSecurity360.it
Nati per intrattenimento o per far ridere, i deepfake si sono trasformati in strumenti malevoli usati per ingannare o raggirare, avendo come obiettivi primari anche imprese ed enti governativi. Ecco un metodo per rilevarli grazie alla stessa intelligenza artificiale usata anche per crearli.

Non vi è giorno in cui, sulla cronaca e nei notiziari, non ci sia un riferimento ad un nuovo caso di deepfake. Spesso vengono generati per intrattenimento o per far ridere, mentre alcuni sono pensati specificatamente e dolosamente per ingannare o raggirare.
I primi attacchi di deepfake hanno preso di mira i personaggi pubblici. Nondimeno, sono diventati obiettivi primari anche le imprese, gli enti governativi e sanitari. Una ricerca recente ha rilevato che poco più della metà delle aziende sono state bersaglio di truffe finanziarie alimentate dalla tecnologia dei deepfake e, di queste, il 43 percento ne è stata vittima.
Sul fronte della sicurezza nazionale, i deepfake possono essere trasformati in armi, consentendo la diffusione di misinformation (informazioni errate), disinformation (disinformazione) e malinformation (informazioni per manipolare) – MDM.
Con l’aiuto dell’intelligenza artificiale è possibile rilevare i deepfake, anche se in alcuni casi non è un processo semplice. Tuttavia, man mano che le tecniche di generazione diventeranno sempre più sofisticate, i metodi di rilevamento continueranno a evolversi, come in un ipotetico gioco del gatto e del topo.
In questo articolo si introduce il tema dell’evoluzione dei deepfake e si illustra un framework per contrastare questa minaccia.
L’evoluzione dei deepfake
La definizione prevalente di deepfake è la seguente: “è una tecnica di sintesi dell’immagine umana basata sull’intelligenza artificiale, specificamente sull’apprendimento profondo (deep learning). Questa tecnica permette di combinare e sovrapporre immagini e video esistenti con video o immagini originali, creando contenuti altamente realistici ma falsi”.
In termini più tecnici, i deepfake utilizzano reti neurali generative avversariali (GAN) per:
- analizzare un vasto dataset di immagini o video di una persona;
- apprendere le caratteristiche distintive del volto, dei movimenti e delle espressioni di quella persona;
- generare nuovi contenuti video o immagini in cui il volto o il corpo della persona sono sostituiti da quelli di un’altra persona o da un’entità completamente nuova.
Il risultato finale è un video o un’immagine che appare estremamente realistico, al punto da essere difficile da distinguere da un contenuto autentico. In sintesi, i deepfake utilizzano le reti neurali profonde per generare immagini o video realistici di persone che dicono o fanno cose che non hanno mai detto o fatto nella vita reale.
La tecnica di generazione prevede il training di un modello di machine learning su un ampio dataset di immagini o video di una persona target e, successivamente, l’utilizzo del modello per generare nuovi contenuti che riproducano in modo convincente la voce o le espressioni facciali della persona.
I deepfake possono essere utilizzati in contesti lavorativi:
- Effetti speciali: Nel settore cinematografico e dei videogiochi per creare effetti speciali realistici.
- Formazione: Per creare simulazioni realistiche di situazioni per l’addestramento in vari campi.
- Arte: Per creare opere d’arte digitali innovative.
- Disinformazione: I deepfake possono essere utilizzati per diffondere notizie false e propaganda.
- Diffamazione: Possono essere utilizzati per danneggiare la reputazione di individui o organizzazioni.
- Frode: Possono essere utilizzati per commettere frodi finanziarie o per impersonare altre persone.
Ma anche in contesti criminali:
I deepfake fanno parte di quel set di tools, basati sull’intelligenza artificiale generativa, in grado di contaminare l’informazione. Il miglioramento delle capacità computazionali dell’intelligenza artificiale rende sempre più ardua l’individuazione dei metodi di manipolazione.
Tra i principali esempi rientrano:
- La manipolazione audio: questa funzionalità è in grado di alterare digitalmente i parametri di una registrazione audio per modificarne il significato. Ciò può comportare la modifica dell’intonazione, della durata, del volume o di altre proprietà del segnale audio. Negli ultimi anni, le reti neurali profonde sono state utilizzate per creare campioni audio, altamente realistici, di persone che dicono cose che in realtà non hanno mai detto.
- La manipolazione delle immagini: questa peculiarità rappresenta il processo di alterazione digitale degli elementi di un’immagine per modificarne l’aspetto e il significato. Ciò può provocare la variazione dell’aspetto di oggetti o persone rappresentati in un’immagine. Di recente, le reti neurali profonde sono state utilizzate per generare immagini completamente nuove che non si basano su oggetti o scene del mondo reale.
- La generazione di testo: questa tecnica implica l’uso di reti neurali profonde, come le “recurrent neural networks” e i modelli basati sui “transformer”, per produrre testo dall’aspetto autentico e che sembra essere stato scritto da un essere umano. Queste tecniche possono replicare lo stile di scrittura e di conversazione degli individui, rendendo il testo generato più credibile.
Come si realizza un deepfake
I deepfake possono essere molto pericolosi, ma, fortunatamente, il processo per generare un deepfake difficilmente rilevabile è ancora molto complesso e oneroso.
Innanzitutto, la creazione di un deepfake richiede l’uso di una o più unità di elaborazione grafica (GPU), come quelle per il gaming, e l’impego di software, spesso distribuito con licenza open source e facilmente scaricabile.
Tuttavia, la realizzazione di un deepfake credibile richiede notevoli competenze nel campo dell’editing grafico e del doppiaggio audio. Inoltre, il lavoro necessario per finalizzare un deepfake credibile richiede un investimento di tempo, nell’ordine di diverse settimane o mesi, da dedicare all’addestramento del modello e alla correzione delle imperfezioni.
Tra i framework open source più utilizzati per creare deepfake troviamo DeepFaceLab e FaceSwap. Sono pubblici, open source e supportati da grandi comunità di sviluppatori, molti dei quali partecipano attivamente all’evoluzione e al miglioramento del software e dei modelli generativi. Questo sviluppo agevolerà la realizzazione di deepfake con maggiore fedeltà e credibilità.
La creazione di un deepfake è un processo che può essere schematizzato in cinque fasi. Per ogni fase è richiesto un componente hardware specifico. Analizziamole osservando la figura sottostante.
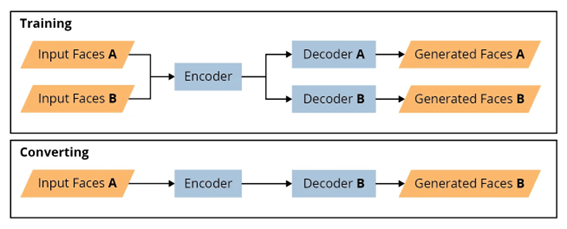
Fasi per la creazione di un Deepfake (Fonte: SEI- Carnegie Mellon University).
- Gathering del video sorgente (CPU): per realizzare un deepfake ad alta risoluzione (p.e. in formato 4K) è necessario acquisire diversi minuti di un filmato originale. I video devono mostrare frame similari sia in termini di espressioni facciali, che dei movimenti oculari e del capo. È, inoltre, importante che le identità sorgente e destinazione si assomiglino. Devono avere la stessa forma e le stesse dimensioni di testa e viso, capelli e barba similari, la stessa tonalità della pelle e sesso. In caso contrario, il processo di sostituzione mostrerà queste difformità come artefatti visivi e, persino, una post-elaborazione ben fatta non sarà in grado di rimuoverli.
- Estrazione (CPU/GPU): in questa fase, ogni video è suddiviso in fotogrammi. All’interno di ogni fotogramma, viene identificato il viso (solitamente utilizzando un modello DNN[1]) e vengono identificati circa 30 punti di riferimento facciali che fungeranno da punti di ancoraggio per il posizionamento delle caratteristiche facciali adoperate dal modello di training.
- Training (GPU): in questa fase, ogni set di facce allineate è immesso nella rete di training. La figura mostra lo schema generale di una rete encoder-decoder utilizzata per il training e per la conversione del modello. Si noti che, dopo la fase di estrazione, tutte le facce di input, allineate e mascherate, vengono immesse nella stessa rete encoder. L’output è una rappresentazione di tutte le facce di input in uno spazio vettoriale di dimensione inferiore, chiamato spazio latente. Successivamente, questi oggetti vengono passati separatamente attraverso le reti decoder per le facce A e B, le quali tentano di generare o ricreare immagini per ogni set di facce. Le facce generate sono, poi, confrontate con le facce originali, viene calcolata la funzione di perdita, si verifica la retro-propagazione e, infine, vengono aggiornati i pesi per le reti decoder ed encoder. Questa ultima azione è utile per i successivi affinamenti. L’utente può decidere di far finire il training dopo aver ispezionato l’output e verificato la qualità, oppure quando il valore di perdita non diminuisce più. Ci sono momenti in cui la risoluzione, o la qualità delle facce in input, impedisce al valore di perdita di raggiungere il valore desiderato. In questo caso, molto probabilmente, nessuna quantità di training o post-elaborazione fornirà un deepfake convincente.
- Conversione (CPU/GPU): il deepfake è generato nella fase di conversione. Per realizzare uno scambio di facce, in cui la faccia A deve essere scambiata con B, viene utilizzato il flusso mostrato nella parte inferiore del processo. In questa fase, le facce di input A, allineate e mascherate, sono immesse nel codificatore. A questo punto, il codificatore ha appreso una rappresentazione per entrambe le facce A e B. Quando l’output del codificatore è passato al decodificatore per B, tenterà di generare la faccia B scambiata con l’identità di A. In questa fase non viene eseguito nessun apprendimento o addestramento. La conversione rappresenta il passaggio unidirezionale di un set di facce date in input attraverso la rete codificatore-decodificatore. L’output del processo è, a sua volta, un set di frame che deve essere assemblato da altri software per diventare un video.
- Post-elaborazione (CPU): questo passaggio richiede molto tempo e abilità. In questa fase possono essere rimossi gli artefatti minori, ma non potranno essere corrette le differenze importanti. Sebbene la post-elaborazione si possa eseguire sfruttando le funzioni di “compositing” e “masking” integrate nei software di deepfake, i risultati saranno diversi da ciò che possa essere auspicabile. Per esempio, DeepFaceLabs consente di regolare in modo incrementale la correzione del colore, della posizione, delle dimensioni e della sfumatura della maschera per ogni fotogramma del video, mentre offre una regolazione della granularità limitata. Mentre, per ottenere una post-elaborazione fotorealistica, è necessario sfruttare i tradizionali effetti multimediali, come i filtri per correggere il colore e per applicare il chroma key, oppure le funzioni per inserire/modificare/cancellare le ombre e le luci del target, presenti nei software di editing fotografico v. PhotoShop o Gimp.
La difficoltà che si può incontrare durante la generazione dei deepfake è fortemente influenzata dai seguenti fattori:
- La risoluzione video di origine e destinazione.
- La risoluzione del deepfake.
- La dimensione della codifica automatica.
- Le dimensioni della codifica.
- Le dimensioni della decodifica.
- I parametri di ottimizzazione.
- La potenza e il tempo di calcolo disponibile.
In sintesi, lo stato dell’arte per la creazione di deepfake comporta: un lungo processo di registrazione o identificazione dei sorgenti esistenti, l’addestramento delle reti neurali, un elevato numero di tentativi ed errori per la ricerca dei migliori parametri e, infine, un estenuante post-elaborazione.
Ognuno di questi passaggi è fondamentale per la realizzazione di un deepfake convincente e realistico. Di seguito sono riportate le principali peculiarità adoperabili per generare un deepfake di qualità:
- hardware GPU adeguato,
- immagini con un’illuminazione sufficientemente uniforme e ad alta risoluzione,
- audio privi di rumore e ad alta risoluzione,
- illuminazione adeguata e abbinata tra le riprese d’origine e di destinazione,
- soggetti con un aspetto simile (forma e dimensioni della testa, stile e quantità di peli sul viso, genere e tonalità della pelle) e modelli di barba sul viso,
- acquisizione video di tutti gli angoli della testa e dell’espressione dei fonemi della bocca,
- utilizzo del corretto modello di training,
- esecuzione di editing post-produzione.
Analisi del problema
Il grafico sottostante mostra il numero annuale di deepfake segnalati o identificati in base ai dati dell’AIAAIC (AI, Algorithmic, and Automation Incidents and Controversies) e dell’AI Incident Database.
Dal 2017, l’anno in cui sono apparsi per la prima volta i deepfake, al 2022, si è registrato un graduale aumento degli incidenti. Mentre, dal 2022 al 2023, si è registrato un aumento nell’ordine di cinque volte maggiore e si prevede che questa tendenza di crescita continui anche negli anni a seguire.
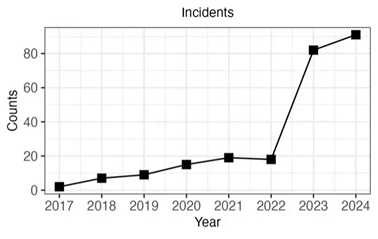
Numeri di deepfake per Anno (Fonte: AI Incident Database).
La maggior parte degli incidenti ha interessato la disinformazione pubblica (60%), la diffamazione (15%), le frodi (10%), lo sfruttamento (8%) e il furto di identità (7%). I principali target presi di mira sono stati: le figure politiche e le organizzazioni (54%), il settore dei media (28%), l’industria (9%) e il settore privato (8%).
Una minaccia in continua evoluzione
I deepfake rappresentano una minaccia in continua evoluzione. Il dato emerge sia dalla lettura del numero di pubblicazioni a tema rinvenibili sulla banca dati “Web of Science”, che dal volume dei repository di codice open source per la generazione di deepfake presenti su “GitHub”, i grafici sottostanti rappresentano una crescita costante.
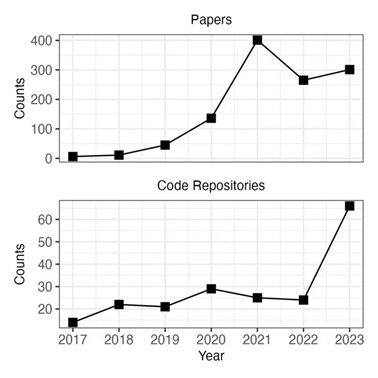
Pubblicazioni e Codice open source sul tema della generazione di deepfake (Fonti: WoS e GitHub).
L’analisi di questi papers ha fatto emergere le quattro principali architetture utilizzate per la generazione di deepfake.
Variational auto encoders (VAE)
Un VAE è costituito da un encoder (codificatore) e un decoder (decodificatore). L’encoder impara a mappare gli input dallo spazio originale (per esempio da un’immagine) verso una rappresentazione latente di dimensione inferiore, mentre il decoder impara a ricostruire una rappresentazione dell’input originale a partire da questo spazio latente.
Nella generazione di deepfake, l’input dell’attore malevolo viene elaborato dall’encoder e, successivamente, il decoder, precedentemente addestrato con i filmati della vittima, ricostruisce il segnale sorgente per adattarlo all’aspetto e alle caratteristiche della vittima-target.
In precedenza, veniva utilizzato l’autoencoder (AE), uno strumento in grado di mappare gli input da un determinato punto fisso nello spazio latente; mentre adesso il VAE traccia gli input attraverso una distribuzione probabilistica, consentendo la generazione di output fluidi e naturali, con un numero inferiore di discontinuità e artefatti[2].
Generative adversarial networks (GANs)
Una GAN è costituita da due reti neurali, la prima denominata “generator” (generatore) e la seconda un “discriminator” (discriminatore), che competono tra loro in un gioco a somma zero.
Il generator crea dati falsi, per esempio una serie di immagini dei volti, mentre il discriminator valuta in maniera ciclica l’autenticità dei dati creati dal primo. Le due reti migliorano la qualità dell’output nel tempo, portando alla generazione di contenuti altamente realistici.
Al termine dell’addestramento, il generator può essere utilizzato per riprodurre volti artificiali partendo da un determinato input[3].
Diffusion models (DM)
I modelli basati sulla diffusione utilizzano un metodo di generazione in cui i dati, come le immagini, vengono progressivamente alterati aggiungendo del rumore. Il modello viene addestrato attraverso la riduzione sequenziale del rumore (c.d. “sequentially denoise”) di queste immagini sfocate.
Una volta che il modello di “denoising” è stato addestrato, può essere utilizzato per generare deepfake partendo da un’immagine composta interamente da rumore e, successivamente, si procede a un graduale miglioramento attraverso il processo di denoising.
I DM sono in grado di produrre immagini dettagliate e fotorealistiche. Il processo di denoising può essere influenzato con input testuali, ciò consente ai DM di produrre output basandosi su specifiche descrizioni relativi ad oggetti o scene[4].
Transformers
L’architettura del transformer utilizza un meccanismo, chiamato di “self-attention”, in grado di specificare il significato dei token in base al loro contesto. Per esempio, ci sono Transformers, molto efficaci per l’elaborazione del linguaggio naturale (NLP), in grado di individuare il significato delle parole in una frase a partire dalle dipendenze sequenziali presenti nel linguaggio.
I transformer sono utilizzati anche nei sistemi text-to-speech (TTS) per individuare le dipendenze sequenziali presenti nei segnali audio, consentendo la creazione di deepfake audio realistici.
Inoltre, i transformer sono alla base dei sistemi multimodali, come DALL-E[5], in grado di generare immagini a partire dalla descrizione di un testo[6].
Architetture per la generazione di deepfake: punti di forza e limiti
Queste architetture presentano punti di forza e dei limiti con conseguenti implicazioni sul loro utilizzo. Ad oggi, VAE e GAN rimangono i metodi più utilizzati, mentre i DM stanno guadagnando terreno.
Questi modelli possono generare immagini e video fotorealistici; per di più hanno la capacità di incorporare informazioni, a partire dalle descrizioni sottoforma di testo, e offrire agli utenti un controllo eccezionale sugli output generati.
Inoltre, i DM possono generare volti, corpi o intere scene. La qualità e il controllo creativo concessi dai DM consentono di realizzare attacchi di deepfake personalizzati e molto più sofisticati di quanto fosse possibile in precedenza.
Un metodo per rilevare i deepfake
Riconoscere un deepfake è diventato sempre più complesso man mano che la tecnologia si evolve, ma esistono alcuni indizi scientifici che possono aiutarci a smascherare queste falsificazioni.
Indizi visivi e tecnici
- Anomalie facciali:
- Movimenti innaturali: Occhi che non battono o battono in modo eccessivo, espressioni facciali rigide o esagerate, labbra che si muovono in modo non sincronizzato con l’audio.
- Incongruenze nei dettagli: Ombre anomale intorno agli occhi o alla bocca, mancanza di dettagli come nei o rughe, colori della pelle innaturali.
- Illuminazione e ombre:
- Incongruenze nell’illuminazione: Ombre che non corrispondono alla direzione della luce, luci che sembrano dipinte sul volto piuttosto che naturali.
- Movimento e distorsioni:
- Movimenti innaturali del corpo: Posture innaturali, movimenti a scatti o troppo fluidi.
- Distorsioni ai bordi: Bordi sfocati o pixelati, soprattutto intorno ai capelli o agli oggetti in movimento.
- Artefatti di compressione:
- Artefatti video: Bande verticali o orizzontali, pixelatura eccessiva, compressione visibile.
Analisi dell’audio
- Desincronizzazione audio-video: La bocca si muove in modo non corrispondente alle parole pronunciate.
- Qualità audio: L’audio può sembrare artificiale, con riverberi innaturali o distorsioni.
Analisi metadati e contesto
- Metadati manipolati: Data e ora di creazione del file modificate, informazioni sulla fotocamera o sul dispositivo non coerenti.
- Contesto: Controllare la fonte del video, cercare altre versioni o testimonianze che confermino o smentiscano il contenuto.
- Analisi forense: Esaminare i pixel individuali per rilevare tracce di manipolazione.
Strumenti in grado di analizzare i deepfake
Esistono diversi strumenti software e online in grado di analizzare i deepfake e identificare potenziali falsificazioni. Questi strumenti utilizzano algoritmi di intelligenza artificiale per rilevare anomalie e incongruenze.
La tecnologia dei deepfake è in continua evoluzione e diventa sempre più difficile da individuare. Pertanto, è fondamentale rimanere aggiornati sulle ultime tecniche di rilevamento e affidarsi a fonti affidabili per l’informazione.
La crescente diffusione dei deepfake ha portato allo sviluppo di una serie di strumenti e tecniche per identificarli. Pertanto, l’efficacia di questi strumenti può variare nel tempo e in base alla complessità dei deepfake stessi. Vediamo i principali:
- Software specializzati:
- Sviluppati da aziende e istituti di ricerca: Offrono analisi approfondite e spesso richiedono competenze tecniche.
- Esempi: Sensity AI, Microsoft Video Authenticator.
- Estensioni per browser:
- Più facili da usare: Consentono di analizzare rapidamente i contenuti direttamente dal browser.
- Esempi: Incogni.
- Piattaforme online:
- Accessibili a tutti: Offrono servizi di verifica gratuiti o a pagamento.
- Esempi: Google Cloud’s Video Intelligence API.
Questi strumenti utilizzano diverse tecniche per rilevare i deepfake:
- Analisi dei pixel: Esaminano i singoli pixel per individuare anomalie nei colori, nelle texture o nelle ombre.
- Riconoscimento facciale: Confrontano le caratteristiche facciali con database di volti reali per individuare incongruenze.
- Analisi del movimento: Valutano la fluidità dei movimenti e la coerenza delle espressioni facciali.
- Rilevamento di artefatti: Cercano artefatti digitali tipici dei processi di manipolazione delle immagini.
- Verifica dei metadati: Esaminano i dati nascosti nei file multimediali per verificare l’autenticità.
Questi strumenti hanno dei limiti che possono produrre:
- Falsa positività: Possono identificare come falsi contenuti autentici, soprattutto se la qualità del video è bassa o se sono presenti compressioni o distorsioni.
- Falsa negatività: Possono non riuscire a rilevare deepfake particolarmente sofisticati.
- Evoluzione continua dei deepfake: I creatori di deepfake migliorano continuamente le loro tecniche, rendendo sempre più difficile il rilevamento.
Un passo importante nella lotta alla disinformazione
Gli strumenti per riconoscere i deepfake sono un passo importante nella lotta alla disinformazione. Tuttavia, non rappresentano una soluzione definitiva. È fondamentale sviluppare una cultura della verifica delle fonti e dell’analisi critica dei contenuti multimediali.
A riguardo è fortemente consigliato:
- Utilizzare più strumenti: Combinare i risultati di diversi strumenti può aumentare l’affidabilità dell’analisi.
- Considerare il contesto: Valutare il contenuto alla luce di altre informazioni disponibili, come la fonte, la data di pubblicazione e le circostanze in cui è stato creato.
- Mantenersi aggiornati: La tecnologia dei deepfake e degli strumenti di rilevamento è in continua evoluzione; quindi, è importante rimanere informati sulle ultime novità.
I rischi e le conseguenze per la sicurezza connessi all’aumento delle tecniche per la generazione e l’utilizzo dei deepfake sono riconosciuti a livello globale.
In tal senso, i threat actor utilizzano queste tecniche per diffondere gli attacchi MDM (misinformation, disinformation e malinformation) con l’intento di influenzare i processi decisionali/politici o minare gli interessi di uno stato, di un’organizzazione o di un’impresa.
Per affrontare questo problema in maniera concreta, diversi centri di ricerca hanno sviluppato tecniche e strumenti per stabilire l’autenticità delle evidenze digitali multimediali, come le immagini, i video e gli audio.
Tra questi studi ho selezionato il metodo elaborato dal CERT del Software Engineering Institute che si basa su tre principi guida:
- Automation: la possibilità di abilitare l’implementazione di decine di migliaia di video su larga scala.
- Mixed-initiative: l’opportunità di sfruttare l’intelligenza umana e quella artificiale.
- Ensemble techniques: per consentire una strategia di rilevamento multilivello.
L’immagine sottostante rappresenta l’integrazione di questi tre principi in un workflow per l’autenticazione dei media digitali incentrato sull’uomo. L’analista caricare uno o più video corrispondenti ad un determinato individuo. Il tool confronta la persona rappresentata in ogni video con un database di individui noti. Se viene trovata una corrispondenza, lo strumento annota l’identità dell’individuo. Successivamente, l’analista può selezionare uno o più rilevatori di deepfake, ogniuno dei quali è stato addestrato per identificare anomalie spaziali, temporali, multimodali e fisiologiche. Se uno dei rilevatori segnala anomalie, lo strumento contrassegna il contenuto per un’ulteriore revisione.
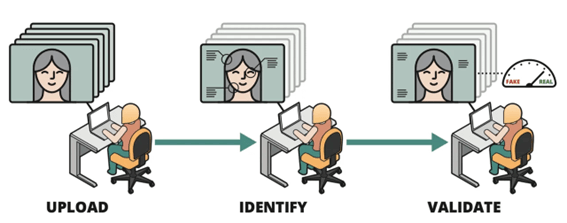
Workflow per l’autenticazione dei media digitali (Fonte: SEI).
Lo strumento consente anche un rapido triage delle immagini e dei video. Questa funzionalità è fondamentale poiché ogni giorno viene caricata una grande quantità di filmati su siti multimediali e sulle piattaforme di social media. Le organizzazioni che utilizzando questo tool sono in grado di sfruttare al meglio il loro capitale umano, indirizzando l’attenzione degli analisti verso le risorse multimediali più critiche.
Conclusioni
Negli ultimi dieci anni sono stati fatti notevoli progressi nel campo dell’intelligenza artificiale generativa, inclusa la capacità di creare e manipolare immagini e video di volti umani. Sebbene esistano applicazioni legittime, queste tecnologie possono essere utilizzate anche per ingannare individui, aziende e organizzazioni governative.
Ovviamente è necessario utilizzare soluzioni tecniche, come i rilevatori di deepfake, per proteggere gli individui e le organizzazioni dalla minaccia del deepfake. Ma le soluzioni tecniche non bastano. È fondamentale aumentare la consapevolezza delle persone a questa tipologia di minaccia, fornendo istruzioni alle imprese, ai consumatori, alle forze dell’ordine e al pubblico in generale.
Parallelamente, i governi stanno implementando le loro legislazioni per migliorare la consapevolezza e la comprensione di queste minacce. Per contrastare la minaccia e per definire i confini all’uso legale, l’Unione europea ha definito una serie di iniziative legislative, dal Regolamento sull’Intelligenza Artificiale al GDPR, per regolamentare i deepfake.
Queste azioni legislative rappresentano un progresso nello stabilire i limiti all’uso appropriato delle tecnologie deepfake e le sanzioni per il loro uso improprio.
Tuttavia, affinché queste leggi siano efficaci, le autorità devono essere in grado di rilevare i contenuti deepfake e questa capacità dipenderà dalla possibilità di accedere ad un set di strumenti più efficaci.
[1] Deep neural network models (reti neurali profonde) sono modelli di apprendimento automatico capaci di rappresentare strutture di dati complesse.
[5] DALL-E è un algoritmo di intelligenza artificiale, sviluppato da OpenAI, capace di generare immagini a partire da descrizioni testuali attraverso la sintografia (il metodo per generare sinteticamente immagini digitali utilizzando l’apprendimento automatico).